RAG system aim to
- Reduce the problem of hallucinated responses from LLMs
- Link sources/references to generated responses
- Remove the need for annotating documents with meta-data.
Takeaway
- Validation of a RAG system is only feasible during operation
- The robustness of a RAG system evolves rather than designed in at the start.
Index process
- If the chunks are too small certain questions cannot be answered, if the chunks are too long then the answers include generated noise.
Query process
- Token limit or rate limit, we need to chain prompts to obtain the answers
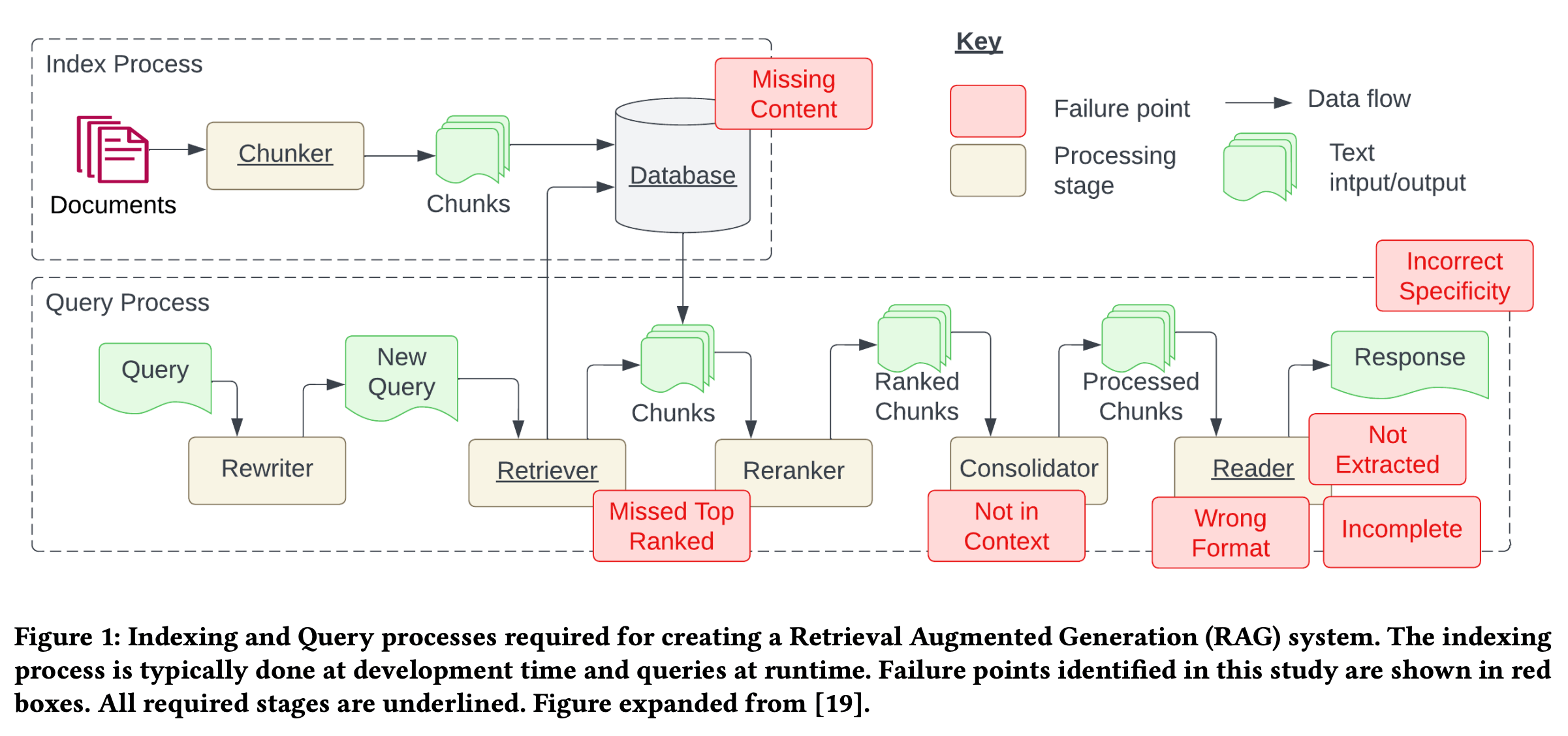
Failures
- Missing Content - No content in the system, LLM should response like "I don't know"
- Missed the Top Ranked Documents - Document is exist but never ranked within the selected top k.
- Not in Context - Consolidation strategy Limitations
- Not Extracted - Answer was presented but LLM failed to extracted. Typically occurs when there is too much noise.
- Wrong format - the question involve extracting information from a specific format such as table.
- Incorrect Specificity - Not specific or too specific to address user's need, for example, on teacher/student AI use-cases, the response must include educational content along with answer, not only the answer itself. Typically occurs when users are not sure how to ask a question.
- Incomplete - The response from LLM is incomplete, for example when you ask "What is the key points of document A, B, and C". A better approach is to ask these questions separately.
Lessons
- Large context get better results - contrary to prior work with GPT3.5
- Adding meta-data improves retrieval - Adding file name, and chunk number into retrieved context helped the reader extract the required information. Useful for chat dialogue
- Open source embedding models perform better for small text
- RAG systems require continuous calibration - due to unknown input received during runtime.
- RAG pipeline configuration is needed - calibrating chunk size, embedding strategy, chunking strategy, retrieval strategy, consolidation strategy, context size, and prompts.
Future research directions
1. Chunking and Embeddings
There are 2 ways of chunking
- Heuristics based (using punctuation, end of paragraph, etc.)
- Semantic chunking (using the semantics in the text to inform start-end of a chunk) Embedding a multimedia and multimodal chunks such as table, figures, formulas may needed
Reference: https://arxiv.org/pdf/2401.05856.pdf