Paper: Mistral 7B
Our model, Mistral 7B, demonstrates that a carefully designed language model can deliver high performance while maintaining an efficient inference.
Mistral 7B outperforms the best open 13B model (Llama 2) across all evaluated benchmarks, and the best released 34B model (Llama 1) in reasoning, mathematics, and code generation.
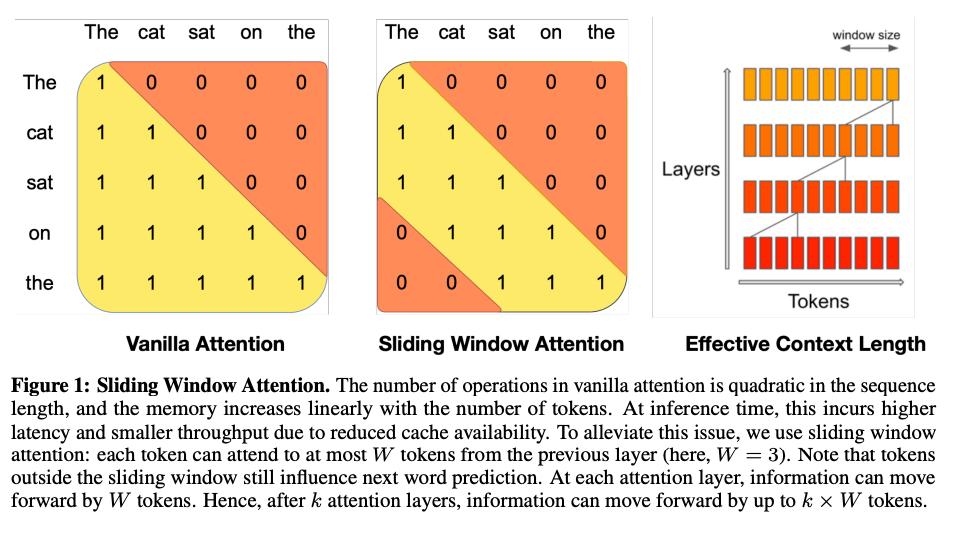
Our model leverages grouped-query attention (GQA) for faster inference, coupled with sliding window attention (SWA) to effectively handle sequences of arbitrary length with a reduced inference cost.
#llm #llm-model #generative-ai