- Netflix มี ranking algorithm หลากหลายตัว และแต่ละตัวถูกสร้างมาด้วยจุดประสงค์ที่ต่างกัน
- Top Picks - เรียงตามความชอบส่วนบุคคล
- Trending Now - ใช้ความ popular เข้ามาคิดด้วย
- เพื่อที่จะวัดผลว่า ranking algorithm แบบไหนสำเร็จ ก็ต้องทำ A/B testing แล้ววัดด้วย metrics ที่สำคัญ
- จำนวนชั่วโมงที่ลูกค้า stream video
- month-to-month subscription retention
- การจะวัดผล metrics ข้างต้น ต้องใช้ sample size ขนาดใหญ่ และ ระยะเวลาที่นาน (> months)
- เค้าเลยต้องหาวิธีการวัดผลแบบใหม่ ซึ่งเสนอว่าให้ทำเป็น 2 stages
- 1 - Pruning - ใช้เพื่อคัดไอเดียที่น่าสนใจ และคาดว่าจะสำเร็จออกมาจากหลายสิบไอเดีย
- 2 - Traditional A/B testing - ใช้เทียบเพื่อวัดผลทีละคู่
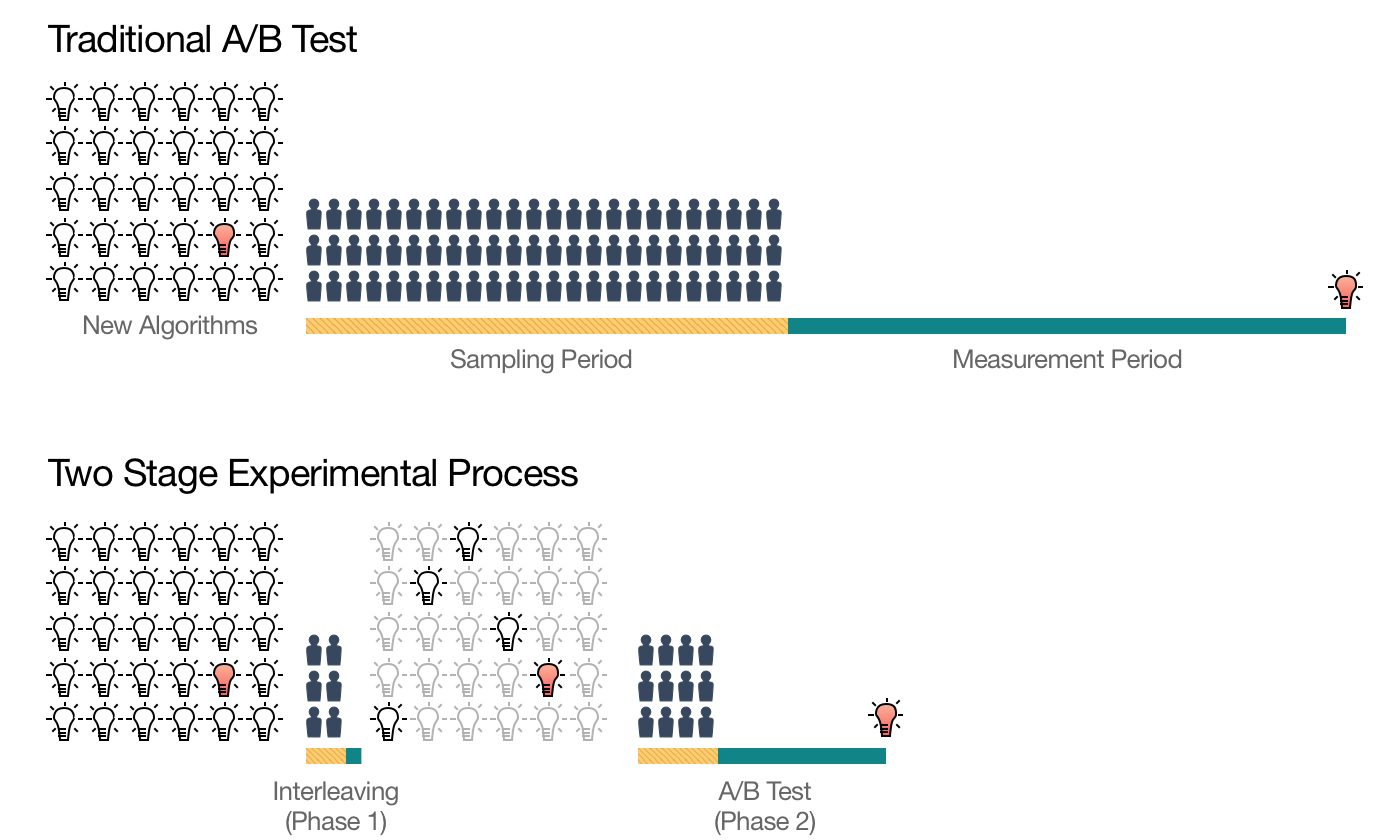
- ในบทความนี้จะพูดถึงส่วน stage 1 - Pruning
- เพื่อจะทำ pruning จะต้องมีคุณสมบัติสองอย่าง
- Highly sensitive กับ ranking algorithm - ใช้ sample size น้อย, วัดผลได้เร็ว
- ของที่ได้มาจะต้องมีความเป็นไปได้ที่จะทำงานได้ดีใน stage 2
- นำเสนอวิธีการ interleaving (Chapelle et al.)
- ทำให้สามารถวัดผล stage แรกในระดับหลักวัน
- เพื่อจะทำ pruning จะต้องมีคุณสมบัติสองอย่าง
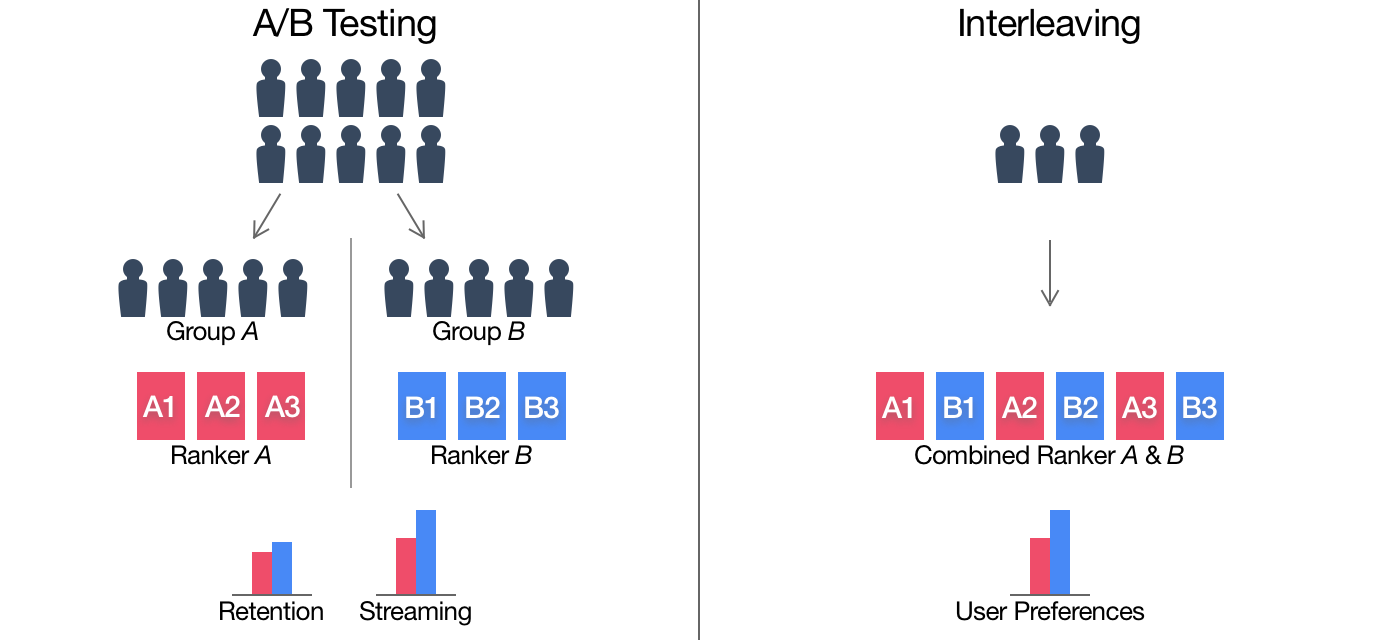
- Interleaving
- ยกตัวอย่างสมมติว่ามีการทดลองนึง ต้องการวัดว่า Coke กับ Pepsi อะไรดีกว่า
- Traditional approaches
- แบ่งผู้เข้าร่วมทดสอบแบบสุ่ม อย่างละครึ่ง
- 50% ได้ Coke อย่างเดียว
- 50% ได้ Pepsi อย่างเดียว
- ตอนจบการทดลองก็วัดดูว่า กลุ่มไหน consume soda มากกว่ากัน
- วิธีแบบนี้มันมีความไม่แน่นอนบางอย่างสามารถเกิดขึ้นได้ แต่กลุ่มการทดลองไม่มากพอ
- คนแต่ละคน มีพฤติกรรมการกินน้ำ soda ที่ต่างกัน ตั้งแต่ไม่ค่อยกินเลย จนถึง กินอย่างหนักหน่วง
- ในคนที่กินหนัก ๆ อาจจะเป็นคนจำนวนน้อยๆ ที่กินเป็นส่วนใหญ่ของการกินทั้งหมด
- ซึ่งทำให้ความ imbalance เล็กน้อย อาจจะส่งผลถึงการสรุปผลที่ผิดพลาดได้
- แบ่งผู้เข้าร่วมทดสอบแบบสุ่ม อย่างละครึ่ง
- Interleaving
- แทนที่จะแบ่งผู้ร่วมทดสอบเป็น 50:50
- เราจะให้ผู้ทดสอบเป็นคนเลือกเอง ว่าจะ consume coke หรือ pepsi (โดยที่ไม่มี brand, label บอก)
- แล้วตอนจบการทดลองเราก็จะวัดว่า cole หรือ pepsi ที่ถูกกินมากกว่ากัน ในระดับของ ผู้ทดสอบแต่ละคน
- ทำให้เราลดความเป็นไปได้ที่จะเกิดจาก imbalance ของพฤติกรรมการบริโภค soda ไปได้
- Traditional approaches
- ยกตัวอย่างสมมติว่ามีการทดลองนึง ต้องการวัดว่า Coke กับ Pepsi อะไรดีกว่า
- Interleaving at netflix
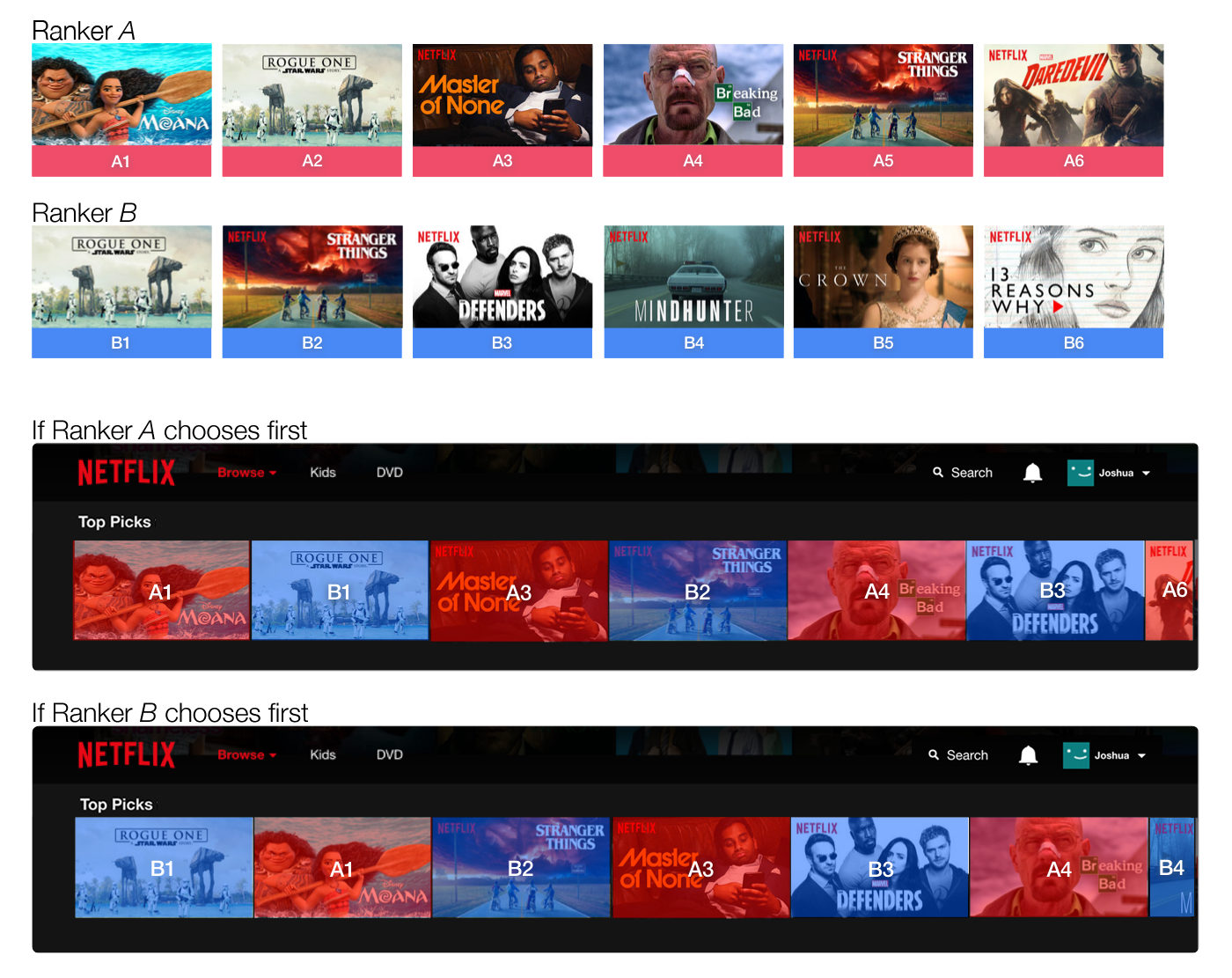
- นำมาใช้โดยที่ แต่ละลูกค้าที่ตรง interleaving experiment แต่ละคน
- จะเห็น algorithm พร้อมกัน 2 ตัว แต่จะแสดงสลับกัน
- แล้วทำการวัดว่าในลูกค้าแต่ละคน streaming hours ของ algorithm ไหนเยอะกว่ากัน (เทียบแบบ relative)
- สิ่งที่ต้องคำนึงคือ position biased, เราจะต้อง make sure ว่า algorithm ทั้งสองตัว ถูกโชว์ในตำแหน่งเดียวกัน เท่าๆ กัน
- Interleaving senstivity
- Netflix ลอง simulate ดู ผลพบว่า interleaving ใช้ผู้เข้าร่วมทดสอบ น้อยมาก (<100x) เพื่อที่จะมีความมั่นใจมากพอ (95% power) ที่จะบอกว่า algorithm นี้ดี
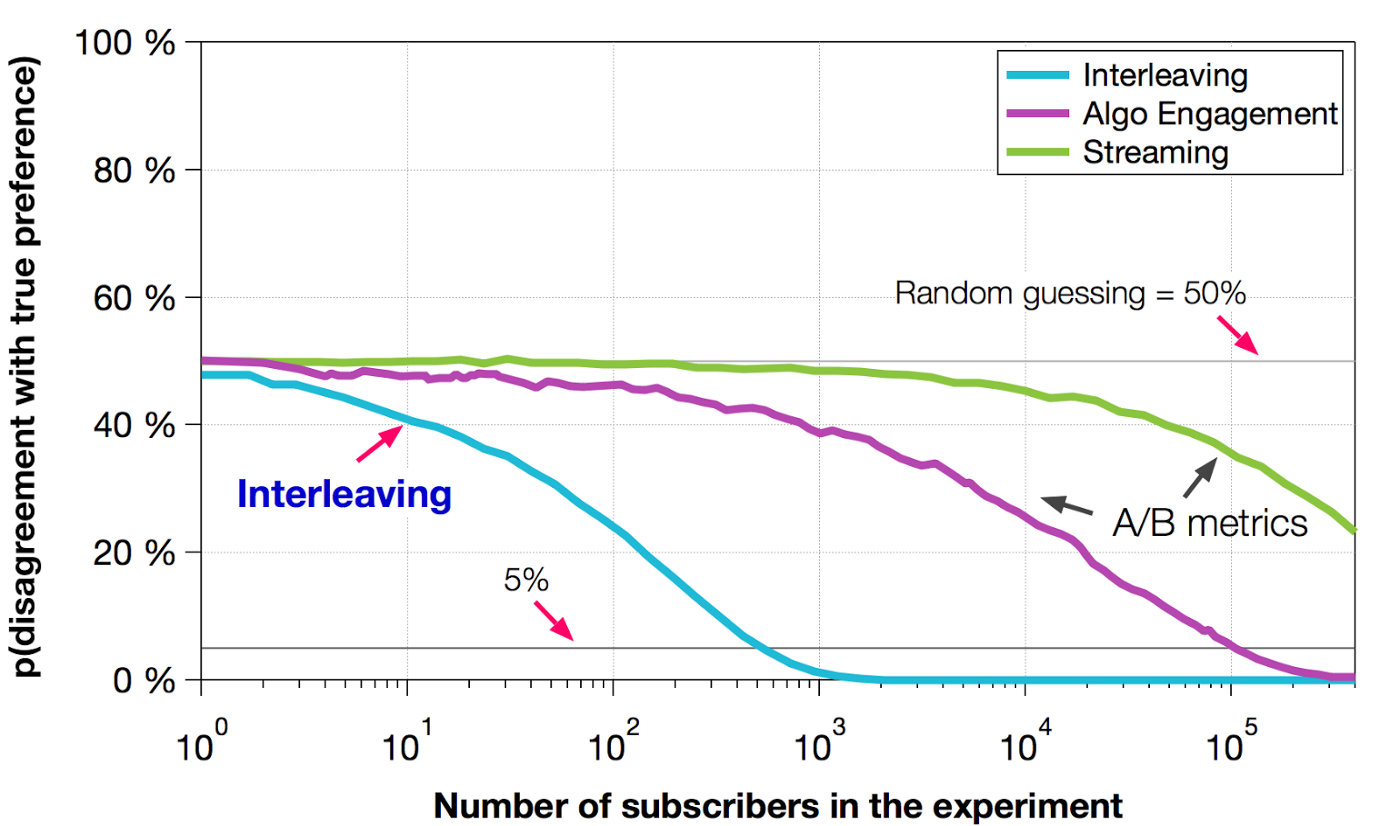
- Netflix ลอง simulate ดู ผลพบว่า interleaving ใช้ผู้เข้าร่วมทดสอบ น้อยมาก (<100x) เพื่อที่จะมีความมั่นใจมากพอ (95% power) ที่จะบอกว่า algorithm นี้ดี
- interleaving success
- Netflix ลองดู correlation เทียบกับการทด A/B testing ธรรมดาก็พบว่า ผลลัพธ์ไปในทางเดียวกัน นั่นคือ ตัวที่มี stream hours สูงจาก interleaving ก็ มักจะมี stream hours สูงใน A/B testing ธรรมดาด้วย
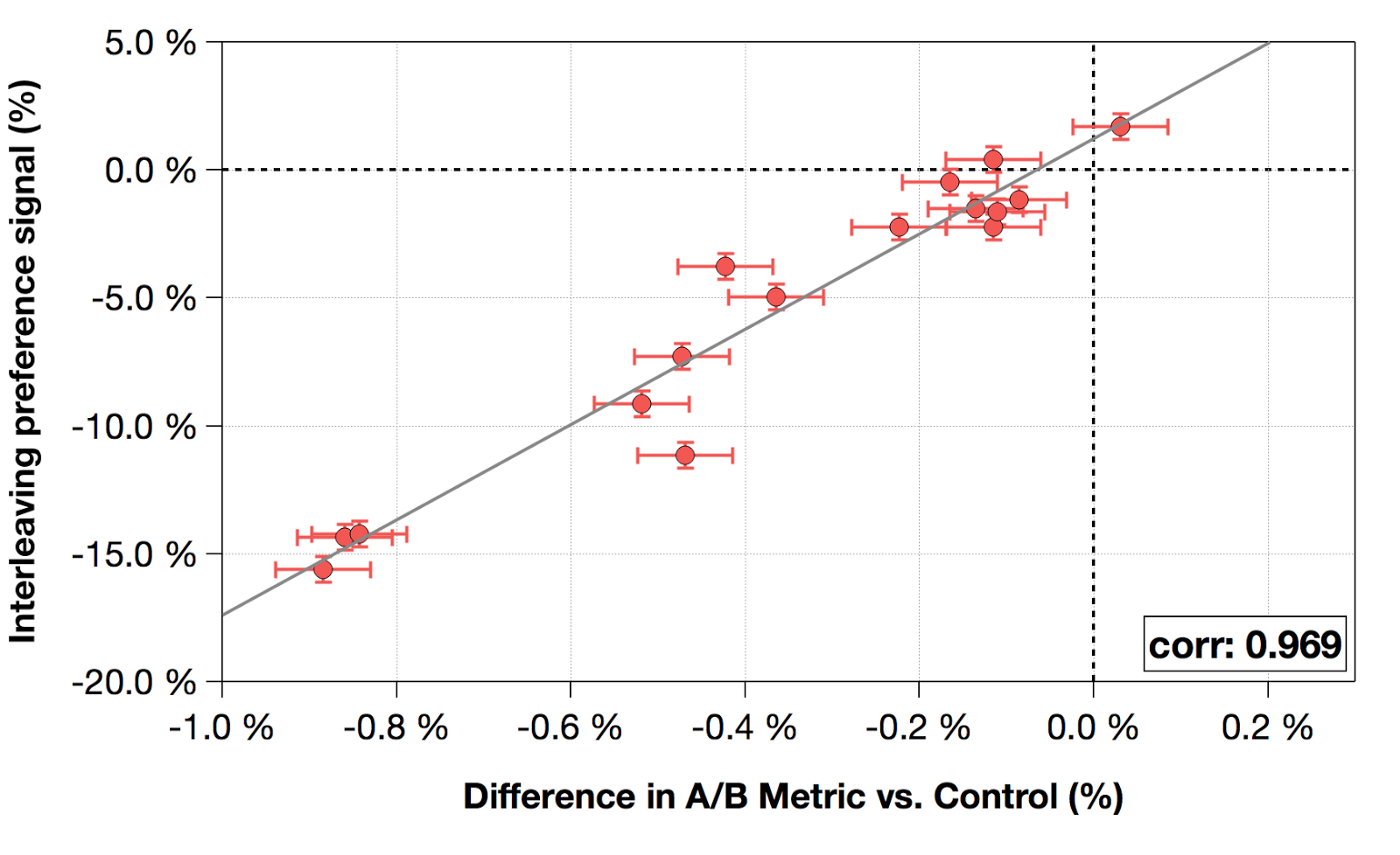
- Netflix ลองดู correlation เทียบกับการทด A/B testing ธรรมดาก็พบว่า ผลลัพธ์ไปในทางเดียวกัน นั่นคือ ตัวที่มี stream hours สูงจาก interleaving ก็ มักจะมี stream hours สูงใน A/B testing ธรรมดาด้วย
- Limitations
- เนื่องจากมันเป็นการวัดระดับบุคคล และเป็นการทดลองสั้นๆ จึงไม่สามารถสรุปผลพวก metrics ระยะยาวได้
- Challenges ของ engineering ที่จะตั้งสร้างระบบการทดลองนี้ขึ้นมา
Reference
#ab-testing #interleaved-experiment