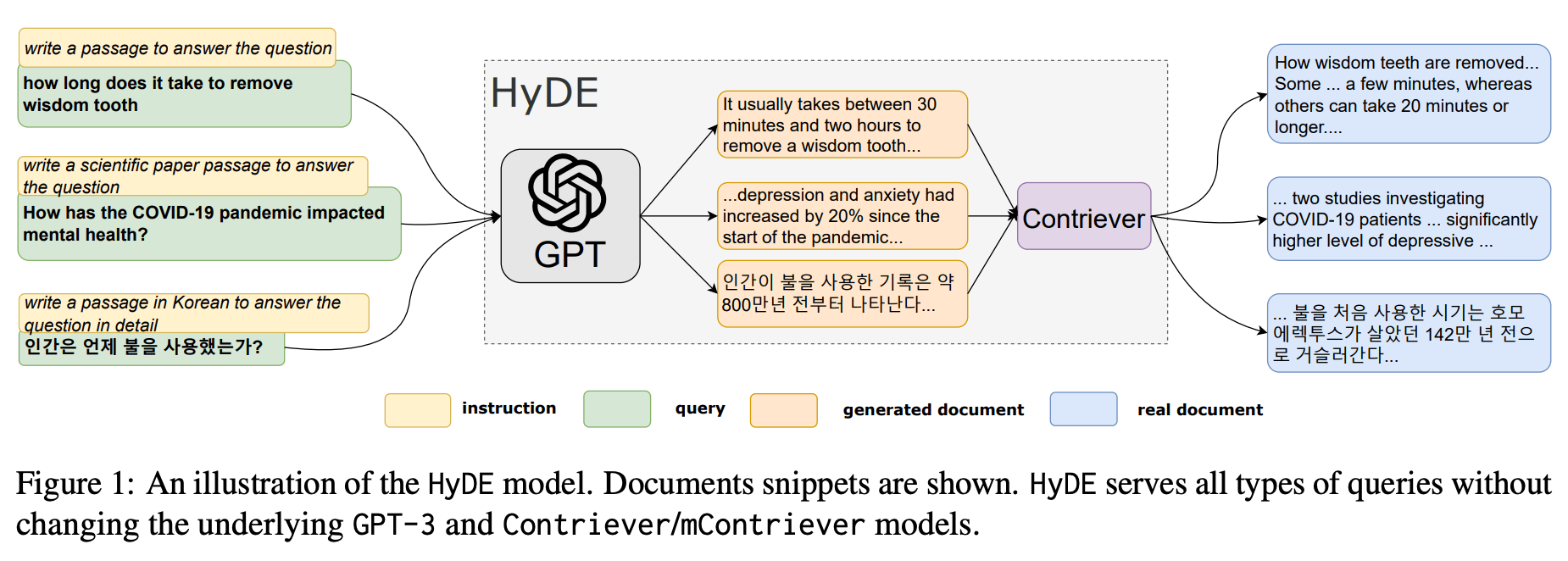
Hypothetical Document Embeddings (HyDE)
- Given a query, HyDE first zero-shot instructs an instruction-following language model (e.g. InstructGPT) to generate a hypothetical document.
- The document captures relevance patterns but is unreal and may contain false details.
- Then, an unsupervised contrastively learned encoder (e.g. Contriever) encodes the document into an embedding vector.
- This vector identifies a neighborhood in the corpus embedding space, where similar real documents are retrieved based on vector similarity.
- This second step ground the generated document to the actual corpus, with the encoder’s dense bottleneck filtering out the incorrect details.
Based on the example from llama-index
Reference: https://github.com/run-llama/llama_index/blob/main/docs/examples/query_transformations/HyDEQueryTransformDemo.ipynb
Failure cases
- HyDE may mislead when query can be mis-interpreted without context.
- HyDE may bias open-ended queries
Reference: https://boston.lti.cs.cmu.edu/luyug/HyDE/HyDE.pdf
#rag #llm #prompting