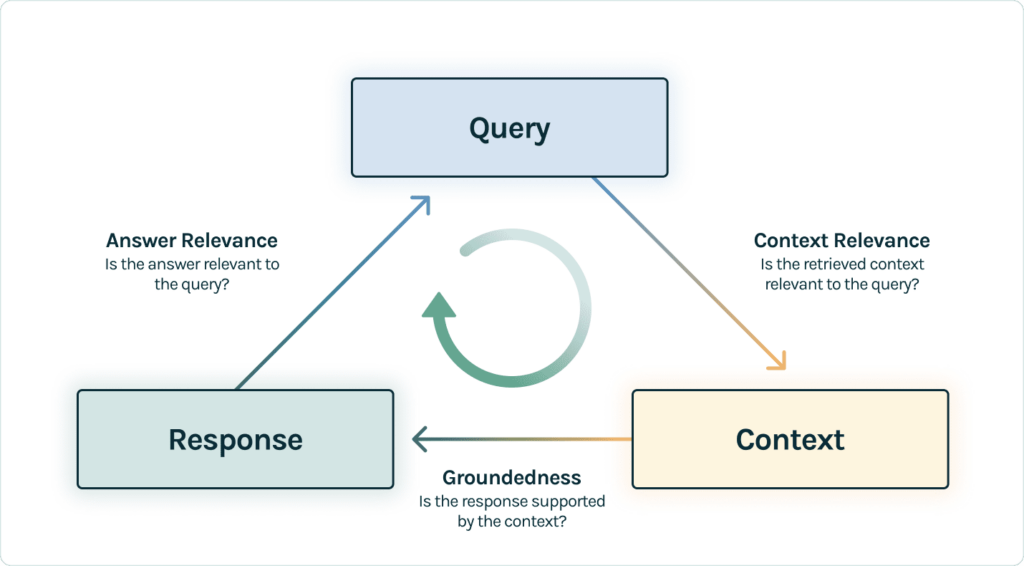
RAG Triad
- Answer Relevance
- Context Relevance
- Groundedness
Answer Relevance
from trulens_eval import Feedback
f_qa_relevance = Feedback(
provider.relevance_with_cot_reasons,
name="Answer Relevance"
).on_input_output()
Context Relevance
to verify the quality of our retrieval, we want to make sure that each chunk of context is relevant to the input query
from trulens_eval import TruLlama
context_selection = TruLlama.select_source_nodes().node.text
import numpy as np
f_qs_relevance = (
Feedback(provider.qs_relevance,
name="Context Relevance")
.on_input()
.on(context_selection)
.aggregate(np.mean)
)
import numpy as np
f_qs_relevance = (
Feedback(provider.qs_relevance_with_cot_reasons,
name="Context Relevance")
.on_input()
.on(context_selection)
.aggregate(np.mean)
)
Groundedness
LLMs are often prone to stray from the facts provided, exaggerating or expanding to a correct-sounding answer. To verify the groundedness of our application, we should separate the response into separate statements and independently search for evidence that supports each within the retrieved contex
from trulens_eval.feedback import Groundedness
grounded = Groundedness(groundedness_provider=provider)
f_groundedness = (
Feedback(grounded.groundedness_measure_with_cot_reasons,
name="Groundedness"
)
.on(context_selection)
.on_output()
.aggregate(grounded.grounded_statements_aggregator)
)
Retrieval
- Sentence-window retrieval
- Auto-merging retrieval