Reference: https://arxiv.org/pdf/2308.10335.pdf
In short:Currently, software engineers should use tools like Co-pilot cautiously.
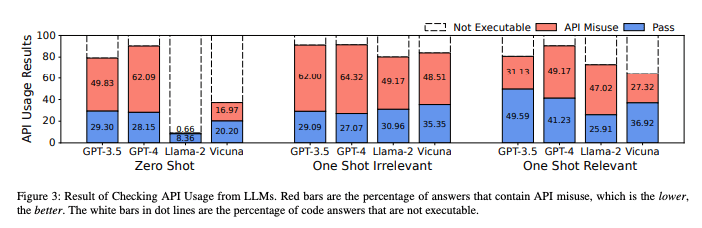
The evaluation results show that even for GPT-4, 62% of the generated code contains API misuses, which would cause unexpected consequences if the code is introduced into real-world software.
Therefore, it is essential to contemplate the code reliability while evaluating the code generation by large language models.
For LLM Practitioners:
- Improvement in the base model helps.
- Fine-tuning the model helps.
- Prompt engineering helps.
Findings:
- Answers to real-world coding questions from state-of-the-art large language models often have API misuse issues.
- Among all answers containing executable code, 57-70% of the code snippets in LLM answers contain API misuse, potentially leading to severe consequences in production.
- Irrelevant short examples do not decrease the API misuse rate but trigger more valid answers, proving effective for benchmarking model performance.
- Some LLMs can learn from correct usage examples, reducing the API misuse rate.
- GPT-4 produces the highest number of answers containing executable code. Different LLMs show varying misuse rates for benchmark APIs.
#llm